老刘并非典型的黑客。1999 年,老刘初次接触开源,当时的他已经是一位 Oracle 的高管。连接他与开源之间的第一道桥梁叫做 TurboLinux,是当时“全球最领先的 Linux 发行版“之一,在 IT 界的火爆程度恐怕不亚于今天的区块链。
然而到了今天,知道的人可能不太多了。百花齐放的 Linux 发行版们从未迎来自己最好的时代,就早早被扫入了历史的角落。
// 无参数无返回值的方法(如果方法没有返回值,不能不写,必须写void,表示没有返回值) public void f1() { System.out.println("无参数无返回值的方法"); }
2、有参数无返回值的方法
/** * 有参数无返回值的方法 * 参数列表由零组到多组“参数类型+形参名”组合而成,多组参数之间以英文逗号(,)隔开,形参类型和形参名之间以英文空格隔开 */ public void f2(int a, String b, int c) { System.out.println(a + "-->" + b + "-->" + c); }
3、有返回值无参数的方法
// 有返回值无参数的方法(返回值可以是任意的类型,在函数里面必须有return关键字返回对应的类型) public int f3() { System.out.println("有返回值无参数的方法"); return 2; }
4、有返回值有参数的方法
// 有返回值有参数的方法 public int f4(int a, int b) { return a * b; }
5、return 在无返回值方法的特殊使用
// return在无返回值方法的特殊使用 public void f5(int a) { if (a>10) { return;//表示结束所在方法 (f5方法)的执行,下方的输出语句不会执行 } System.out.println(a); }
主要作用是完成对类对象的初始化工作。可以执行。因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。如果我们自己添加了类的构造方法(无论是否有参),Java 就不会再添加默认的无参数的构造方法了,这时候,就不能直接 new 一个对象而不传递参数了,所以我们一直在不知不觉地使用构造方法,这也是为什么我们在创建对象的时候后面要加一个括号(因为要调用无参的构造方法)。如果我们重载了有参的构造方法,记得都要把无参的构造方法也写出来(无论是否用到),因为这可以帮助我们在创建对象的时候少踩坑。
abstract class AbstractStringBuilder implements Appendable, CharSequence { /** * The value is used for character storage. */ char[] value; /** * The count is the number of characters used. */ int count; AbstractStringBuilder(int capacity) { value = new char[capacity]; }}
public final native Class<?> getClass()//native方法,用于返回当前运行时对象的Class对象,使用了final关键字修饰,故不允许子类重写。 public native int hashCode() //native方法,用于返回对象的哈希码,主要使用在哈希表中,比如JDK中的HashMap。 public boolean equals(Object obj)//用于比较2个对象的内存地址是否相等,String类对该方法进行了重写用户比较字符串的值是否相等。 protected native Object clone() throws CloneNotSupportedException//naitive方法,用于创建并返回当前对象的一份拷贝。一般情况下,对于任何对象 x,表达式 x.clone() != x 为true,x.clone().getClass() == x.getClass() 为true。Object本身没有实现Cloneable接口,所以不重写clone方法并且进行调用的话会发生CloneNotSupportedException异常。 public String toString()//返回类的名字@实例的哈希码的16进制的字符串。建议Object所有的子类都重写这个方法。 public final native void notify()//native方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。 public final native void notifyAll()//native方法,并且不能重写。跟notify一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。 public final native void wait(long timeout) throws InterruptedException//native方法,并且不能重写。暂停线程的执行。注意:sleep方法没有释放锁,而wait方法释放了锁 。timeout是等待时间。 public final void wait(long timeout, int nanos) throws InterruptedException//多了nanos参数,这个参数表示额外时间(以毫微秒为单位,范围是 0-999999)。 所以超时的时间还需要加上nanos毫秒。 public final void wait() throws InterruptedException//跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念 protected void finalize() throws Throwable { }//实例被垃圾回收器回收的时候触发的操作
public class test1 { public static void main(String[] args) { String a = new String("ab"); // a 为一个引用 String b = new String("ab"); // b为另一个引用,对象的内容一样 String aa = "ab"; // 放在常量池中 String bb = "ab"; // 从常量池中查找 if (aa == bb) // true System.out.println("aa==bb"); if (a == b) // false,非同一对象 System.out.println("a==b"); if (a.equals(b)) // true System.out.println("aEQb"); if (42 == 42.0) { // true System.out.println("true"); } } }
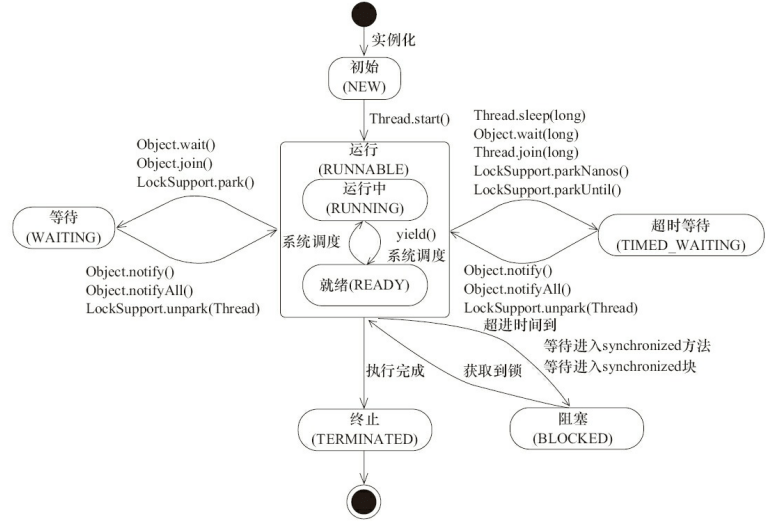
进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。简单来说,一个进程就是一个执行中的程序,它在计算机中一个指令接着一个指令地执行着,同时,每个进程还占有某些系统资源如 CPU 时间,内存空间,文件,输入输出设备的使用权等等。换句话说,当程序在执行时,将会被操作系统载入内存中。
线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。从另一角度来说,进程属于操作系统的范畴,主要是同一段时间内,可以同时执行一个以上的程序,而线程则是在同一程序内几乎同时执行一个以上的程序段。